
October 2025
The Problem We Walked Into
I'm not going to lie-when we started this project in early 2024, I thought we'd be done in six months. We're now in late 2025, and we're just hitting our stride.
The healthcare network we worked with spans three hospital groups serving about 3.5 million people. On paper, they'd "merged" five years ago. In practice? Their systems were still completely isolated.
Here's what that actually meant: An elderly patient comes into the ER after a fall. The doctor can see she's allergic to penicillin in their hospital system. Great. What they can't see:
- The home safety assessment social services did two weeks ago
- That she's on experimental chemo from the cancer center across town
- Her community pharmacy records showing she's not actually taking half her meds
This isn't theoretical. This happened regularly. And yes, people got hurt because of it.

Why Their Existing Setup Was Broken
They already had integration infrastructure... an interface engine processing millions of HL7 v2 messages daily. The problem? It was all point-to-point connections and push-based messaging.
Think of it like this: If someone sent you an important email three months ago but it got caught in your spam filter, that information doesn't exist for you. That's how their systems worked.
The real headache was connecting the social care department. Their "modern" integration was a custom VPN tunnel that converted CSV files into HL7 messages. It took three developers two months to build. We had 200 primary care clinics that needed connecting. Do the math.
The research team had it worse. They wanted specific data points (tumor sizes, biomarker values) but everything was locked in PDF pathology reports. Someone was literally copying data into spreadsheets by hand.
What We Actually Built
The Facade Strategy (Or: How to Not Replace Everything)
First question everyone asks: "Did you rip out all the old systems?"
No. Absolutely not. That would've cost tens of millions of dollars and taken years.
Instead, we built what's called a FHIR facade. Think of it as a translator that sits on top of the old databases. The legacy systems stay exactly where they are, but now when someone makes a modern API call (like GET /Patient/12345), the facade translates that into whatever arcane SQL query or HL7 lookup the old system needs.
This worked great for simple data. For the complex oncology stuff? We needed something heavier.
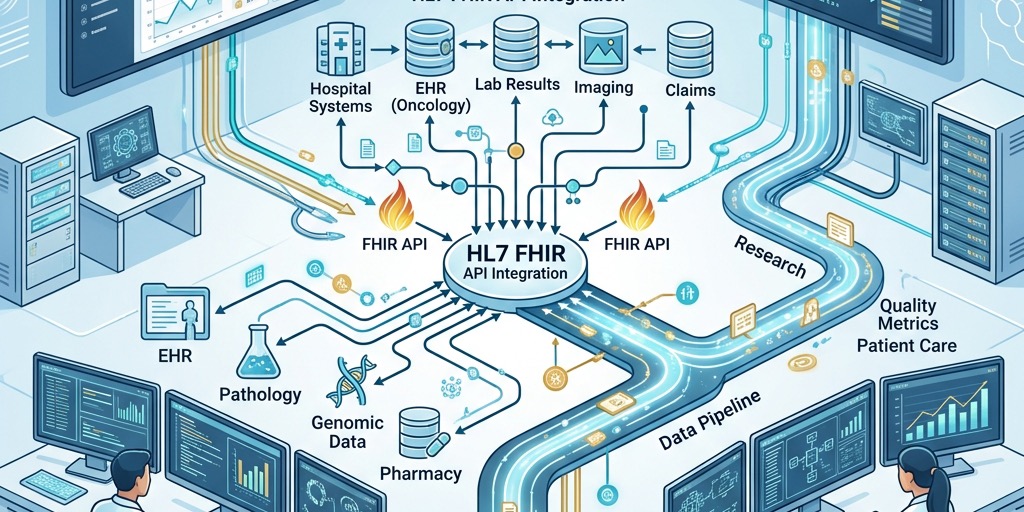
The Oncology Pipeline (Where Things Got Complicated)
Pathology reports came in as PDFs, XML files, sometimes even scanned images. We built a pipeline:
- Ingestion - Reports flow through Kafka streams
- Parsing - ETL service rips apart the PDFs and XML
- FHIR Mapping - Convert to proper FHIR resources (Patient, Observation, Specimen)
- Anonymization - Strip personally identifiable info before research access
Sounds clean when I list it like that. Reality? We spent three months just figuring out how to reliably extract tumor dimensions from PDFs because every pathologist formats their reports differently.
The Identity Crisis
Before we could share any clinical data, we had to solve the "Who is this person?" problem.
Hospital A knew "Martha J. Jones" (ID: 111). Social services knew "Martha Jones" (ID: 999). The cancer center knew "M. Jones" (ID: ABC-7734).
We implemented a Master Patient Index using FHIR's Patient resource and the $match operation. Now when you query for a patient, the system finds the "golden record" and links all three identities.
First time we ran it on production data, we found about 8,000 duplicate patient records. Some people had four different IDs across the network.

Where We Actually Innovated: Social Care Integration
This was the hardest part, and honestly, where I'm most proud of what we did.
Hospital systems use standardized medical codes like SNOMED-CT and LOINC. Social care records? Free text notes like "Patient walks with difficulty" or "Needs help with shopping."
We used FHIR's CarePlan and Consent resources in ways I haven't seen elsewhere:
CarePlan: The social worker's support plan becomes visible directly in the hospital discharge nurse's screen. Not as a PDF attachment but as structured, actionable data.
Consent: This one's critical. We built granular consent controls so a patient could authorize sharing their HIV status with the hospital but not with the nursing home administrator.
For the free text problem, we ran everything through an NLP engine that mapped "walks with difficulty" to the proper SNOMED code for impaired mobility. Suddenly, when a doctor searched for mobility issues, social care records appeared-even though they started as plain text.
Security (Or: How We Didn't Create a Data Breach Nightmare)
Opening up APIs across organizations makes security folks nervous. Rightfully so.
We used SMART on FHIR, which basically delegates authorization to OAuth 2.0. Here's how it works in practice:
A doctor clicks "View Community Record" in their Epic system. That launches our app in an iframe, passing along context (which user, which patient). Our authorization server checks their credentials and permissions. If they're legit, they get an access token scoped to exactly what they need. Maybe read-only access to Observations, nothing else.
We had one close call in testing where someone's token wasn't expiring properly. That got fixed fast.

What Actually Changed
18 months after launch:
Duplicate lab tests dropped 30% because ER doctors could finally see recent results from specialty centers. That's real money and real patient comfort. Nobody wants to get stuck with a needle twice.
Discharge planning went from four days to a day and a half. Turns out when the hospital discharge team can instantly see the social care plan, they stop playing phone tag for three days.
Medication errors down 18%. We aggregated hospital prescriptions and community pharmacy dispensing into one MedicationStatement view.
The research team reduced cohort assembly time from four months to two weeks. They're actually publishing papers now instead of spending all their time wrangling data.

What We Learned (The Hard Way)
Don't map everything. We initially tried to convert every single field in every legacy database to FHIR. Three months in, we'd made almost no progress. We pivoted hard. Only map what's clinically critical for your specific use case. Everything else can wait for v2.
Validate ruthlessly. Early on, bad data kept crashing our apps. We implemented strict validation at the API gateway. If a system sent a Patient resource without a birthdate (mandatory in our profile), we rejected it with a detailed error message. Systems cleaned up their data quality real fast.
The cultural problem is harder than the technical one. Social workers didn't want another login, another system. We embedded our FHIR viewer directly into their existing case management tool using an iframe. They didn't even know they were using "new technology." It just worked inside their familiar interface.
What's Next
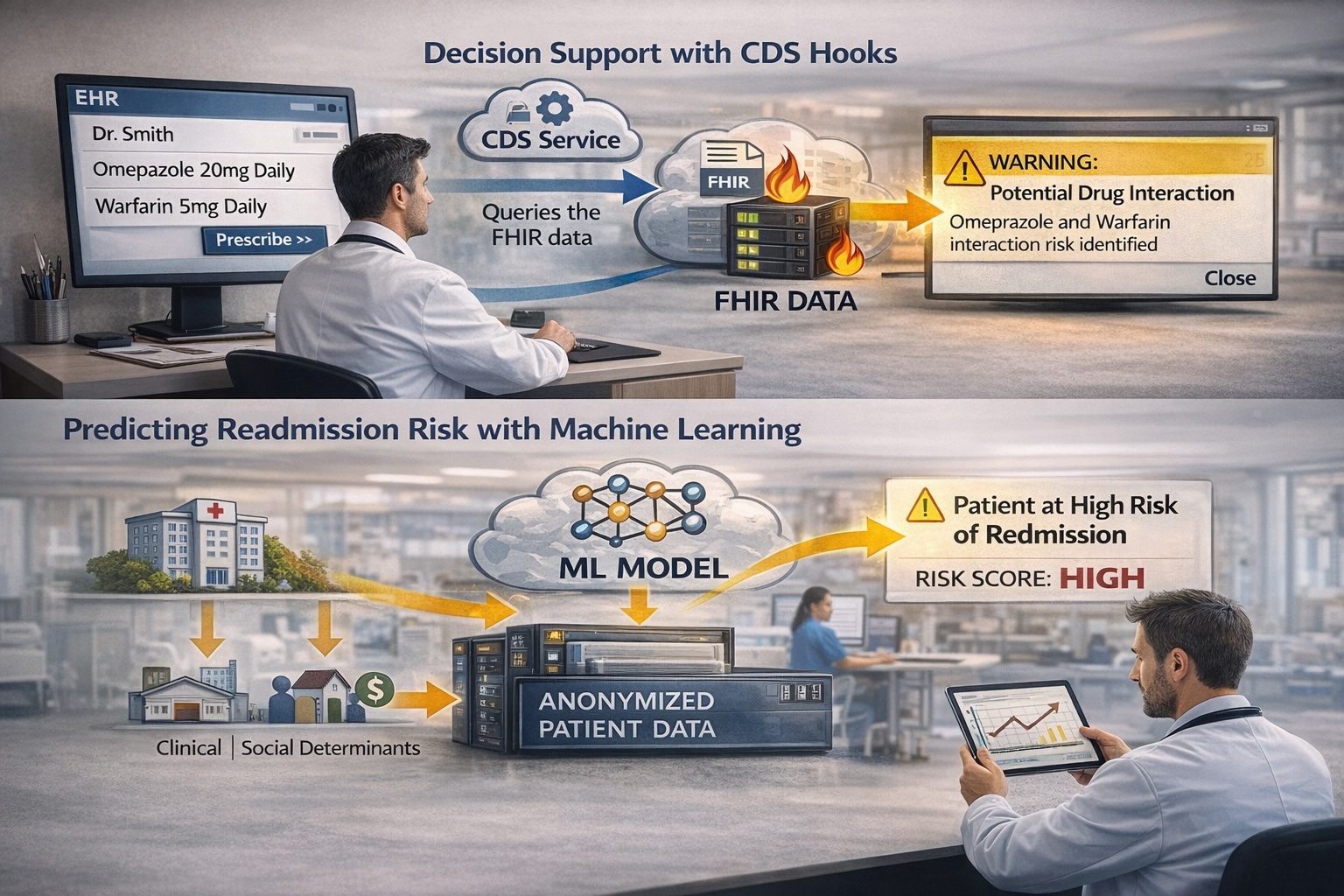
With the foundation in place, we're moving into decision support. We're implementing CDS Hooks. When a doctor prescribes a drug, a service checks the FHIR data for contraindications and can pop up a warning in real-time.
We're also training ML models on the anonymized data to predict readmission risk. Combining clinical and social determinants data. Something impossible when everything was siloed.
If you're considering a project like this: budget more time than you think, get buy-in from clinical staff early, and please don't try to solve every problem in version 1.
Happy to talk through specifics if you're dealing with similar challenges. The mistakes we made? You don't have to repeat them.
Want to discuss your interoperability challenges? Let's connect.