
The Bill That Nobody Owns
Ask a typical engineering VP who owns the AWS bill in their organization and you'll get a long pause. "DevOps, probably? Or maybe Finance?" In a monolithic architecture, that ambiguity was manageable. One application, one team, one bill. You could see the costs, understand the drivers, and act on them.
Microservices broke that model completely. When your platform is 200 independent services - each with its own compute, storage, networking, and data transfer costs - the cost picture fragments alongside the architecture. A spike in your monthly statement could be one service misbehaving, a change in data egress patterns, a forgotten load balancer from a deprecated feature, or the compounding effect of a dozen small inefficiencies no single team noticed because each one looked irrelevant in isolation.
This is not a tooling problem. AWS Cost Explorer exists. Budgets alerts exist. Tagging policies exist. Organizations that treat cloud cost control as a configuration exercise invariably discover that the tooling was never the constraint. The constraint is cultural and organizational: who is responsible, who has the visibility, and who has the authority to act.

What FinOps Actually Is (And What It Is Not)
FinOps - Financial Operations for cloud infrastructure - is a practice, not a product. The FinOps Foundation defines it as "a cultural practice that brings technology, finance, and business together to align spending and business value." That definition sounds abstract until you see what it means in practice: engineering teams that actually understand unit economics, finance teams that can interpret AWS service codes, and a shared accountability model that makes cost performance a first-class concern alongside reliability and security.
What FinOps is not: installing CloudHealth or Apptio and calling it done. Third-party cost visibility tools are useful, but they are inputs to a FinOps practice, not the practice itself. Organizations that purchase tooling without the underlying cultural and process changes typically see a short-term improvement in cost visibility (which is real and valuable) followed by plateau - costs remain high because nobody has changed how engineers make decisions about resource allocation.
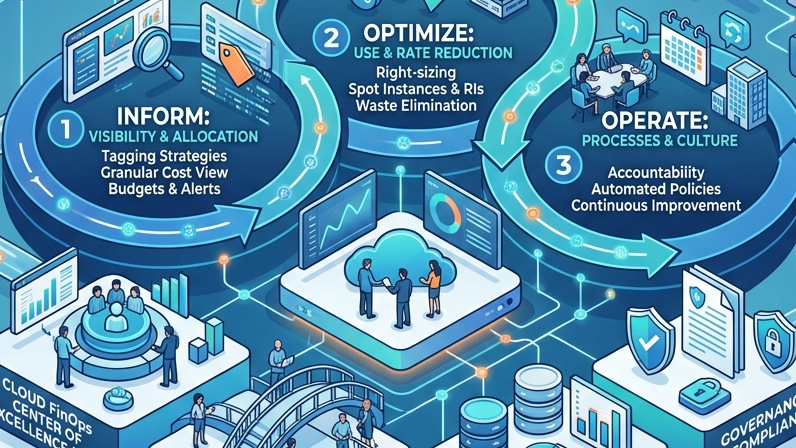
The three pillars of a mature FinOps practice are Inform (make costs visible and attributable), Optimize (identify and act on inefficiencies), and Operate (embed cost discipline into ongoing delivery processes). Most organizations can get to Inform quickly. Moving through Optimize and into Operate requires sustained organizational commitment that most cost-cutting initiatives never develop.
Tagging Strategies That Actually Work
Resource tagging is the foundation of cost visibility in a microservices environment, and it is also where most organizations fail first. The failure mode is predictable: a well-intentioned tagging policy is defined, partially enforced, and then gradually erodes as teams under delivery pressure skip the discipline. Six months later, 40% of resources are untagged or tagged inconsistently, and cost attribution becomes an exercise in estimation rather than fact.
Effective tagging requires treating tags as infrastructure, not metadata. That means:
- Enforcement at provisioning time. If your Infrastructure as Code (Terraform, CloudFormation, CDK) does not require specific tags as mandatory inputs, tags will be optional in practice regardless of policy. Use custom policy rules, AWS Organizations SCPs, or Sentinel policies to reject resources without required tags at the point of creation.
- A minimal, stable taxonomy. The temptation is to tag everything with maximum granularity - environment, team, product, cost center, project, customer, application, and tier. In practice, taxonomies that exceed six to eight mandatory tags become unmanageable. Start with:
env,service,team,cost-center, andproduct. Extend only when the business case is concrete. - Automated remediation for drift. Even with enforcement at provisioning, legacy resources, manually created resources, and AWS-managed resources (certain RDS snapshots, for example) resist tagging. Use Lambda-based automated tagging remediation that runs on a schedule and flags or corrects deviations.
- Tag inheritance modeling. In a microservices environment, a single application might have compute in EC2 or ECS, storage in S3 and RDS, networking through ALB and NAT gateway, and orchestration through Step Functions or EventBridge. The cost of "the order processing service" spans all of these. Tag inheritance patterns in your IaC modules ensure that all resources provisioned by a single module carry the same service and team attribution.

Showback vs. Chargeback: Choosing the Right Model
Once tagging enables cost attribution, the next organizational question is what to do with that information. Two dominant models exist: showback and chargeback.
Showback makes costs visible to teams without financial consequence. Engineering teams see their monthly cloud spend, understand trends, and can optimize voluntarily. This model works well in organizations where engineering culture is already cost-conscious and where product teams have genuine ownership of their services.
Chargeback goes further: attributed costs are actually billed back to business units or product lines, affecting their P&L or budget. This creates stronger financial incentives to optimize but introduces complexity. Teams start gaming attribution to minimize their visible costs. Infrastructure shared services (networking, observability, security tooling) need allocation models. Finance teams need new processes to handle internal billing. Arguments about allocation methodology consume engineering leadership time that could be spent on delivery.
The practical answer for most organizations is a phased approach: implement showback first to build literacy and identify the highest-impact optimization opportunities without creating adversarial dynamics. After 12-18 months, when teams understand the cost landscape and have demonstrated willingness to act on it, introduce selective chargeback for the largest and most attributable cost centers.
One concrete data point: a 400-person engineering organization that implemented showback in their microservices platform saw a 23% reduction in cloud spend within eight months - not because of chargeback pressure, but because engineers who could see their costs for the first time found and fixed inefficiencies they genuinely had not known existed.
Reserved Instance and Savings Plan Optimization
On-demand pricing is appropriate for variable, unpredictable workloads. For baseline capacity in production microservices environments, it represents a significant overpayment - typically 40-60% more than equivalent Reserved Instance or Savings Plan coverage.
The challenge is that RI optimization in a microservices environment is substantially more complex than in a monolithic one. You have more instance types, more services with different utilization patterns, and more teams with independent scaling behavior. Committing to reserved capacity requires confidence in forward-looking demand that many teams understandably lack.
A few principles that navigate this well:
- Compute Savings Plans over instance-type RIs. Compute Savings Plans provide 66% discount versus on-demand and apply automatically across any EC2 instance family, ECS, and Lambda - which is exactly the flexibility you need in a microservices environment where instance types shift as services evolve.
- Cover the baseline, not the peak. Analyze trailing 90-day utilization data and identify the capacity floor - the compute that runs continuously regardless of load. Cover that with Savings Plans or RIs. Keep spike capacity on-demand. Even covering 60-70% of baseline dramatically reduces blended rates.
- Automate the review cycle. Utilization patterns change as services evolve. Set a quarterly calendar commitment to review RI coverage, expiry dates, and utilization rates. Organizations that skip this accumulate unused reservations and miss renewal windows at material cost.

The Governance Layer: Making FinOps Stick
The mechanics of tagging and reserved capacity are solvable engineering problems. The harder challenge is governance: embedding cost discipline into delivery processes so that optimizations compound over time rather than degrading when attention moves elsewhere.
Governance in a FinOps context means establishing clear decision rights (who can approve resource types above certain cost thresholds), accountability rhythms (weekly or monthly cost reviews at the team and platform level), and cost guardrails in the delivery process (architecture review gates that include cost modeling for significant new infrastructure).
Practical governance mechanisms that consistently work:
- Cost anomaly detection with escalation paths - automated alerts when spend for any tagged service exceeds a defined percentage above baseline, routed to the owning team and their engineering lead
- Architecture Review Board criteria that include a cost efficiency assessment for any new service or significant infrastructure change above a defined monthly spend threshold
- FinOps champions embedded in each product team - typically a senior engineer with both technical and commercial awareness who participates in cross-team FinOps working groups
- Monthly cost stand-ups between engineering leads and finance, focused on trend analysis rather than blame allocation

How GTEMAS Approaches Cloud Cost Governance
When GTEMAS joins a platform engineering engagement, cloud cost governance is not a separate workstream - it is embedded in the delivery model from day one. We build tagging enforcement into every IaC module we contribute. We instrument showback dashboards as part of observability setup. We conduct FinOps reviews as part of architectural decision documentation.
The result is that cost visibility and optimization capability grows with the platform rather than being retrofitted later at significant friction. Clients typically see meaningful cost reductions within the first two quarters of engagement - not through dramatic architectural changes, but through the compounding effect of dozens of small optimizations that become visible once attribution is working properly.
Cloud bills do not have to be the inevitable consequence of architecture complexity. They are an engineering problem, and like most engineering problems, they respond to systematic attention. If your organization is navigating fragmented cost visibility in a microservices environment, we would be glad to discuss how a structured FinOps approach might apply to your situation.